

Aprendizaje profundo (Deep Learning)
El aprendizaje profundo, también conocido cono redes neuronales profundas, es un aspecto de la inteligencia artificial (AI) que se ocupa de emular el enfoque de aprendizaje que los seres humanos utilizan para obtener ciertos tipos de conocimiento. En su forma más simple, el aprendizaje profundo puede considerarse como una forma de automatizar el análisis predictivo.
Mientras que los algoritmos tradicionales de aprendizaje automático son lineales, los algoritmos de aprendizaje profundo se apilan en una jerarquía de creciente complejidad y abstracción. Para entender el aprendizaje profundo, imagine a un niño cuya primera palabra es “perro”. El niño aprende lo que es (y lo que no es) un perro señalando objetos y diciendo la palabra “perro”. El padre dice “Sí, eso es Perro” o “No, eso no es un perro”. Mientras el niño continúa apuntando a los objetos, se vuelve más consciente de las características que poseen todos los perros. Lo que el niño hace, sin saberlo, es aclarar una abstracción compleja (el concepto de perro) construyendo una jerarquía en la que cada nivel de abstracción se crea con el conocimiento que se obtuvo de la capa precedente de la jerarquía.
Los programas informáticos que utilizan el aprendizaje profundo pasan por el mismo proceso. Cada algoritmo en la jerarquía aplica una transformación no lineal en su entrada y utiliza lo que aprende para crear un modelo estadístico como salida. Las iteraciones continúan hasta que la salida ha alcanzado un nivel de precisión aceptable. El número de capas de procesamiento a través de las cuales los datos deben pasar es lo que inspiró la etiqueta de profundidad (“deep”).
En el aprendizaje tradicional de las máquinas, el proceso de aprendizaje es supervisado y el programador tiene que ser muy, muy específico al decirle a la computadora qué tipos de cosas debe buscar para decidir si una imagen contiene un perro o no contiene un perro. Este es un proceso laborioso llamado extracción de características y la tasa de éxito de la computadora depende totalmente de la capacidad del programador para definir con precisión un conjunto de características para “perro”. La ventaja del aprendizaje profundo es que el programa construye el conjunto de características por sí mismo sin supervisión. Esto no es sólo más rápido, sino que por lo general es más preciso.
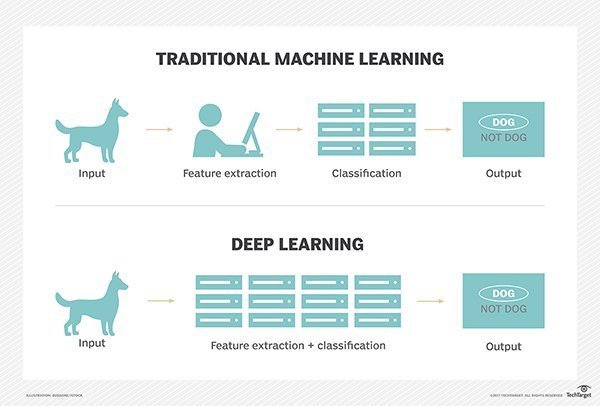
Inicialmente, el programa de computadora podría ser provisto de datos de entrenamiento, un conjunto de imágenes para las cuales un humano ha etiquetado cada imagen “perro” o “no perro” con metaetiquetas. El programa utiliza la información que recibe de los datos de entrenamiento para crear un conjunto de características para el perro y construir un modelo predictivo. En este caso, el modelo que la computadora crea por primera vez podría predecir que cualquier cosa en una imagen que tenga cuatro patas y una cola debería estar etiquetada como “perro”. Por supuesto, el programa no es consciente de las etiquetas “cuatro patas” o “cola”, simplemente buscará patrones de píxeles en los datos digitales. Con cada iteración, el modelo predictivo que crea el equipo de cómputo se vuelve más complejo y más preciso.
Debido a que este proceso imita el pensamiento humano, el aprendizaje profundo a veces se conoce como aprendizaje neuronal profundo o redes neuronales profundas. A diferencia del niño pequeño, que tardará semanas o incluso meses en comprender el concepto de “perro”, un programa informático que utiliza algoritmos de aprendizaje profundo puede mostrar un conjunto de entrenamiento y ordenarlo a través de millones de imágenes, identificando con precisión qué imágenes tienen perros en tan solo unos minutos.
Con el fin de lograr un nivel aceptable de precisión, los programas de aprendizaje profundo requieren acceso a inmensas cantidades de datos de entrenamiento y poder de procesamiento, ninguno de los cuales estaba fácilmente disponible para los programadores hasta la era de los grandes datos y la computación en nube. Debido a que la programación del aprendizaje profundo es capaz de crear modelos estadísticos complejos directamente a partir de su propia salida iterativa, es capaz de crear modelos predictivos precisos a partir de grandes cantidades de datos no etiquetados y no estructurados.
Esto es importante a medida que el internet de las cosas (IoT) continúa haciéndose más penetrante, porque la mayoría de los datos que los seres humanos y las máquinas crean están desestructurados y no están etiquetados. Los casos de uso de hoy para el aprendizaje profundo incluyen todos los tipos de aplicaciones de análisis de big data, especialmente aquellos enfocados en el procesamiento del lenguaje natural (NLP), traducción de idiomas, diagnóstico médico, señales de comercio bursátil, seguridad de redes e identificación de imágenes.